Byte Latent Transformer

Is this the end of Tokenization in LLMs ?
Large Language Models (LLMs) have made groundbreaking progress in natural language processing by relying on tokenization-based architectures.
What the hell is Tokenization ?
Tokenization is the process of breaking down text into smaller units called tokens, such as words, subwords, or characters, that the model can understand and process. For example, a word like “unbelievable” might be split into smaller parts like “un”, “believe”, and “able”. This step helps reduce the vocabulary size but introduces challenges with out-of-vocabulary tokens and unpredictable byte-level data.
Limitations
However, these models come with limitations, such as fixed vocabularies, inefficiencies in inference, and struggles with out-of-vocabulary tokens or byte-level complexities.
Tokenization-based models often require extensive preprocessing and can falter when encountering unpredictable, low-entropy data.
Why make changes to current ?
Tokenization has previously been essential because directly training llms on bytes is prohibitively costly at scale due to long sequence lengths. Prior works mitigate this by employing more efficient self-attention or attention-free architectures. However, this primarily helps train small models. At scale, the computational cost of a Transformer is dominated by large feed-forward network layers that run on every byte, not the cost of the attention mechanism
Tl;DR — Research of Meta: Byte Latent Transformer
To address these challenges, this research introduces the Byte Latent Transformer (BLT), a novel byte-level LLM architecture that eliminates the need for tokenization while achieving state-of-the-art performance at scale.
BLT is significant because it combines efficiency, robustness, and flexibility when compared to traditional models.
This is achieved by encoding raw bytes into dynamically sized patches, which serve as the fundamental units of computation.
What are Patches now ?
Patches are split based on how complex the next byte of data is. If the data looks more complex, BLT uses more computing power to process it. This approach makes the model faster and better at handling tricky tasks, like reasoning or understanding uncommon patterns.
What’s unique in the study ?
The study presents the first flop-controlled scaling study of byte-level models, scaling up to 8B parameters and 4T training bytes.
The results demonstrate the feasibility of training models directly on raw bytes without relying on fixed vocabularies.
BLT significantly outperforms tokenization-based models for fixed inference costs by dynamically increasing both patch size and model size when needed.
In summary, the BLT architecture not only addresses current limitations of LLMs but also offers a path to more scalable, efficient, and robust language models for diverse data complexities.
Details of the Research
Introduction
The Byte Latent Transformer (BLT) is a tokenizer-free architecture that processes raw byte data directly, solving many issues faced by traditional tokenization-based models.
Why it matters:
- Tokenization introduces biases and struggles with unfamiliar or noisy data.
- Training on raw bytes was previously inefficient due to long sequence lengths and high computational costs.
What BLT does:
- Eliminates tokenization by dynamically grouping bytes into patches based on complexity.
- Efficiently allocates resources where needed, reducing computational costs.
- Provides a scalable and robust solution for training large models without relying on fixed vocabularies.
To help you efficiently allocate compute, BLT dynamically groups bytes into patches based on complexity. Unlike tokenization, there’s no fixed vocabulary for these patches. Arbitrary byte groups are mapped into meaningful representations using lightweight encoders and decoders. This approach ensures smarter resource use, making BLT more efficient than traditional tokenization-based models.
Compute Efficiency
Traditional LLMs allocate the same amount of compute to every token, which can be inefficient. BLT changes this by dynamically allocating compute only where it’s needed. For example:
- Predicting the end of a word is simple and needs less compute.
- Predicting the first word of a sentence is complex and requires more resources.

BLT uses three transformer blocks: two small byte-level local models and one large global latent transformer. By analyzing the entropy (complexity) of the next byte, BLT groups data into patches with similar complexity, ensuring smarter and more efficient compute allocation.
Overview
A byte-level latent transformer (BLT) model trained without fixed-vocabulary tokenization, scaling up to 8B parameters and 4T training bytes.
Key Results
- Matches Llama 3’s performance in a** flop-controlled** setting but achieves upto 50% fewer inference flops
- Demonstrates improved handling of long-tail data and input noise.
- Shows enhanced character-level understanding in orthography, phonology, and low-resource translation tasks.
Core Innovations :
- Flop Efficiency: Dynamic compute allocation improves training and inference efficiency.
- Scaling advancement : Allows simultaneous scaling of model size and patch size without increasing inference flops.
- Robustness : BLT models excel at noisy inputs and capture sub-word details missed by token-based LLMs.
Impact
New Scaling dimensions of LLMs are coming, optimised compute and improved performance in un-explorerd byte-level tasks
How to do Patching ?
Segmenting bytes into patches allows BLT to dynamically allocate compute based on context.

The above figure shows different methods for segmenting bytes into patches. A patching function segments a sequence of bytes into a smaller sequence of patches, where each byte is marked to indicate the start of a new patch.
For both token-based and patch-based models, the computational cost of processing data depends primarily on the number of steps executed by the main Transformer. In BLT, this corresponds to the number of patches needed to encode the data with a given patching function. The average patch size is the key factor that determines the cost of processing data during training and inference.
The three introduced patching methods are:
Strided Patching Every K bytes:
Strided patching groups bytes into fixed-size patches of size k, similar to the approach used in MegaByte. This method is simple to implement for both training and inference, offering a straightforward way to adjust the average patch size and control computational cost. How it also some limitations.
Space Patching
Space patching improves upon strided patching by creating new patches after any space-like bytes, which often serve as natural boundaries for linguistic units in many languages. This method allocates a latent transformer step (and compute) to model every word, ensuring consistency in patching across sequences.
Key benefit:
Focused Compute Allocation: Flops are effectively allocated to challenging predictions, such as the first byte of a word. For example, predicting the first byte of “Mozart” in response to a question like “Who composed the Magic Flute?” is significantly harder than predicting subsequent bytes.
Entropy Patching: Using Next-Byte Entropies from a Small Byte LM
Instead of using rule-based heuristics like whitespace, entropy patching takes a data-driven approach to determine patch boundaries by identifying high-uncertainty next-byte predictions.
Here’s how it works:
- A small byte-level auto-regressive language model (LM) is trained on the BLT training data.
- Next-byte entropy estimates are computed under the LM distribution, indicating uncertainty in predicting the next byte.
- Patch boundaries are placed where entropy (uncertainty) is high, ensuring more compute is allocated to difficult-to-predict regions.
Improvement in Scaling ?
A New Scaling trend is on the horizon at byte-level models to guide the further development of BLT models. The scaling study addresses key limitations of prior research on byte-level models by:
- Compute-Optimal Training: Comparing trends within the compute-optimal training regime.
- Large-Scale Training: Training 8B models on substantial datasets, up to 1T tokens (4T bytes), and evaluating performance on downstream tasks.
- Inference-Cost Control: Measuring scaling trends under settings where inference costs are controlled.
Parameter Matched Compute Optimal Scaling Trends
The BLT architecture shows scaling trends that fall between Llama 2 and Llama 3 when we use significantly larger patch sizes.
While Llama 2 and 3’s BPE tokenizers average 3.7 and 4.4 bytes per token, BLT achieves similar performance trends with an average patch size of 6 or 8 bytes.
Key insights for you:
- Inference Efficiency: Inference flops are inversely proportional to patch size. A patch size of 8 bytes results in ~50% savings in inference flops.
- Performance Scaling: Larger patch sizes perform better as model size and data scale increase.
- Trends with Scale: At 1B parameters, BLT with a patch size of 8 starts off weaker than Llama 2, but by 7B scale, it outperforms Llama’s BPE-based approach.
Future Potential: Larger patch sizes might perform even better as you scale up model size and training compute, suggesting feasibility for further scaling.
Patches Scale Better Than Tokens
With BLT models, we can simultaneously increase model size and patch size while maintaining the same training and inference flop budget and keeping the training data constant. This is a unique advantage over token-based models, which face efficiency tradeoffs tied to fixed-vocabulary tokenization.
Longer patch sizes reduce compute, allowing you to reallocate resources to scale the global latent transformer since it runs less often.
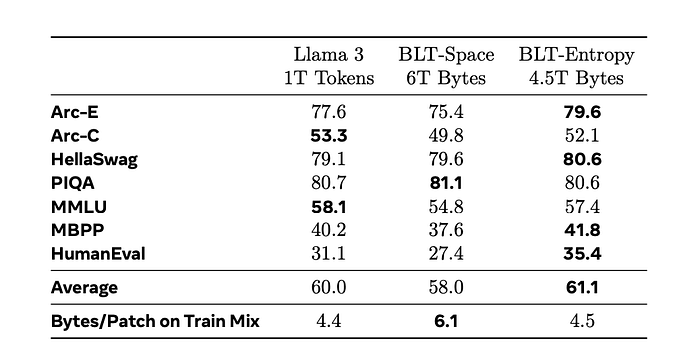
Here are the key takeaways:
- Fixed Inference Scaling Study: They tested whether larger models taking fewer steps on larger patches outperform smaller models taking more steps. BLT-Entropy models with patch sizes of 6 and 8 bytes were compared to equivalent Llama 2 and 3 models.
- Scaling Performance:
- At small training budgets, token-based (BPE) models perform better.
- BLT models quickly surpass token-based models beyond the compute-optimal regime, demonstrating better scaling trends.
- BLT performs particularly well in larger flop classes, where patch size 8 models show steeper scaling improvements.
- Efficiency with Patch Size 8:
- Larger patch sizes only impact flops from the Latent Transformer, not the byte-level modules, making scaling efficient.
- As parameters grow 20x from 400M to 8B, BLT’s local model parameters only double, allowing improved scaling.
Scaling both patch size and model size simultaneously improves performance, with trends persisting and even improving at larger model scales. This highlights BLT’s efficiency advantage over traditional token-based architectures.
References :
- Original Paper — Paper