Embeddings & Vector Stores: A Beginner’s Guide

All you need to know to get started with Embeddings, cool terms like RAG, GraphRAG, etc
Introduction
Machine Learning (that consists of LLMs as well) thrives on diverse data — images, audio, text, and more.
While Large Language Models are really good at conversational and providing answers but the problem is they are not good when it comes to real time data or data that they are not trained upon. That’s where it is require to feed data to LLMs but how to do that without training.
Well we’ll go through the following to understand these efficiently :
- Understanding Embeddings: Why they are essential for handling multimodal data and their diverse applications.
- Embedding Techniques: Methods for mapping different data types into a common vector space.
- Efficient Management: Techniques for storing, retrieving, and searching vast collections of embeddings. •
- Vector Databases: Specialized systems for managing and querying embeddings, including practical considerations for production deployment.
- Real-World Applications: Concrete examples of how embeddings and vector databases are combined with large language models (LLMs) to solve real-world problems.
But first, let’s understand the basics:
Why Embeddings are Important (and what the hell they are firstly)
- Embeddings are numerical representations of real world data such as text, speech, image or videos. (or in other words words → converted to numbers, like for example if I assign (a-1, b-2, c-3, and so on…)
- The name embeddings refer to similar concept in mathematics where one space (in this case text, speech, audio) can be mapped, or embedded, into another space [let’s say numbes (1,2,3,…)].
Embeddings are expressed as low-dimensional vectors where the geometric distance between two vectors in the vector space is a projection of the relationship and semantic similarity between the two real-world objects that the vectors represent.
Let’s hold and understand what this means :
- Vector → Vector is a general term for an object with magnitude and direction, often used in math and physics. OR A vector is a quantity that has both direction and magnitude (size). For example, Think of it like walking 5 steps north — the 5 steps is the magnitude, and north is the direction.
- Embedding → Just a vector only that the cools guys at ML and NLP use, to say the same fucking thing, that represents data in vector space (another cool word that represents → Mathematical Graph that we used to use to create 2-parallel lines to get passing grades in 5th standard). So from now on, I’ll use vectors and embeddings as synonyms, just for ease.
- Why Embedding → Well computers (or Machine Learning Algorithms are nothing but mathematical equations that requires numbers to make sense, and embeddings are the perfect common language for both humans and machines (algorithms), to understand the meaning of data.
- How different objects can be used as embeddings : For example, the word ‘computer’ has a similar meaning to the picture of a computer, as well as to the word ‘laptop’ but not to the word ‘car’. These low -dimensional numerical representations of real-world data significantly help efficient large scale data processing and storage by acting as a means of lossy compression of the original data (or low representation or compressed representation while preserving quality and meanings) while retaining its important semantic properties.
- Another important reason for usage to Vectors is how easy it is to find relevant or similar objects by just calculating the distance between any two vectors, or just looking to nearby vectors.
Figure-1: Embeddings representation of words
So that’s we cover the basics of embeddings/vectors but when data is present in text format only. What about multi-modal data (data consists of text, images, audios, etc combined)
Embeddings also shine in the world of multimodality. Many applications work with large amounts of data of various modalities: text, speech, image, and videos to name a few.
Joint embeddings are when multiple types of objects are being mapped into the same embeddings space, for example retrieving videos based on text queries.
These embedding representations are designed to capture as much of the original object’s characteristics
as possible.
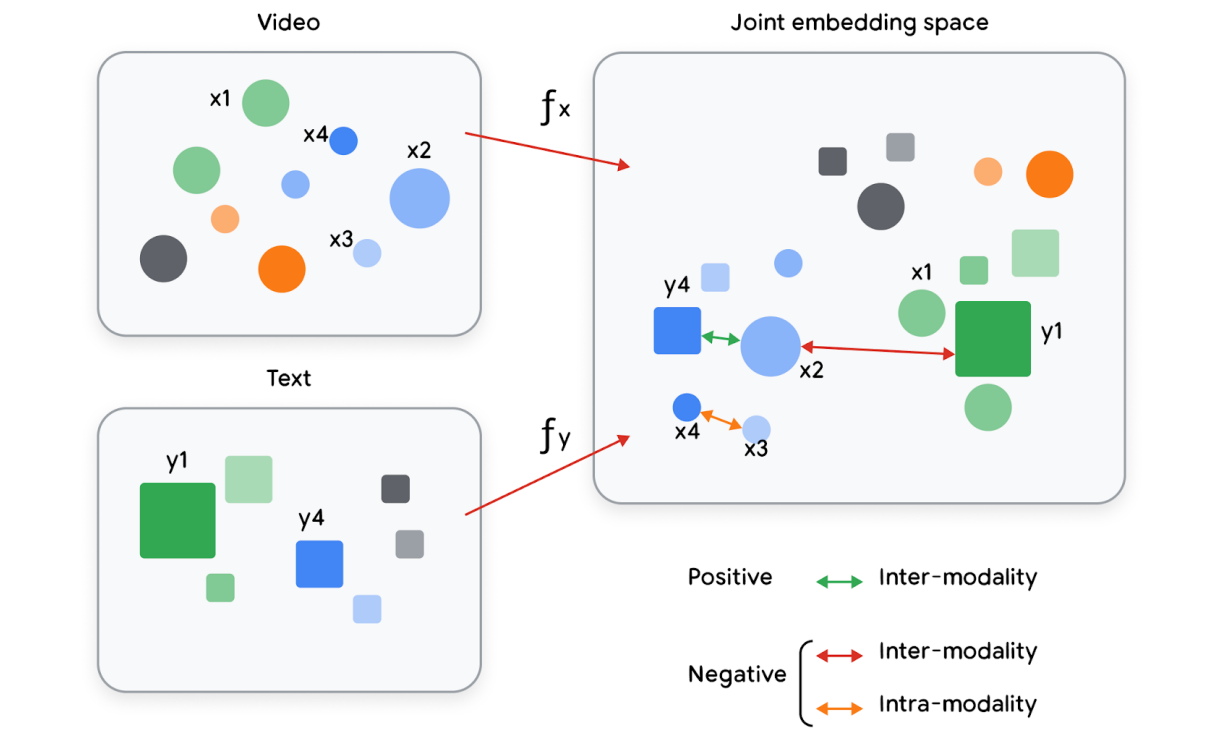
Embeddings representing multi modal and combining them into one joint vector space to show similar relationships
that’s how it represents that’s it.
Now let’s move to some examples, most famous one Search.
So let’s say I have a thousands of documents present on my google drive and I want to find some information that might be stored in 69th document so there are two ways to find the information.
- I’ll take leave from my work and starting download and reading each document till I reach 69th document which will take from days to months depending upon the length of the documents
- OR I implement an system that has been connected to my data and I can simply search for that information with natural language and it will automatically go through all the documents and will bring me the information alongside with the document where it is stored.
Second one seems fine, let’s deep dive into it.
Search : A perfect example of embeddings and vector stores (DBs)
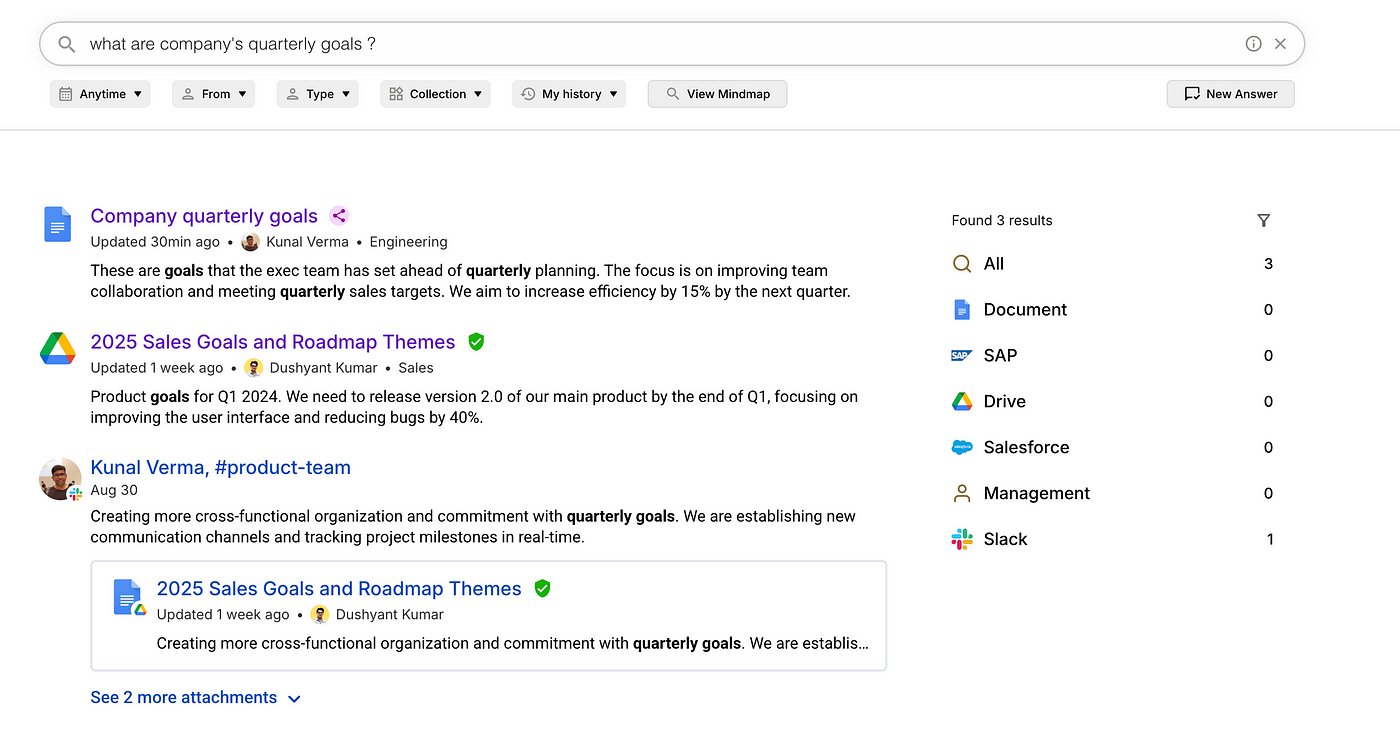
Figure — 2: A quick example of our product at InfraHive.ai — where we used Embeddings and RAG to build a platform that can be connected to all data sources and brings infromation with simple natural language
The goal is to find relevant documents in a large corpus given a query from the user.
Before explaning how we built this systems internally (here I’ll show you only for the documents but it can be scaled to other data sources as well like Google Drive, Excels, even servers as well) — here are some more cools terms (that I’m going to use to look and sound smart).
- RAG (Retrieval-Augmented Generation): A method where a model retrieves relevant information before generating a response.
Why RAG ? Well LLMs are really good at giving us answers but the problem is what if the answer lies in your 1000-page document, and you don’t want to train an LLM from scratch, well here comes the RAG — it is a framework that allows you supply information to LLMs before having an answer from it - Chunk: A small piece of text split from a larger document to make processing easier. (if you remember that LLMs oftens says, too long context or you parsed a lot of information to LLMs, well to fix that problem we break the information into smaller portions called chunks and process called chunking)
- Index (Indexing): Organizing chunks into a searchable format so relevant ones can be quickly found. In simple terms think of it Table of contents OR Index of any book.
Explanation : Imagine you split a book into paragraphs (chunks), then create a list where each paragraph is connected to keywords or vector representations. When a question is asked, the system searches this index to find the best matching paragraph — fast and efficiently.
In LLM, this often means converting chunks into embeddings (vectors) and storing them in a vector database for fast similarity search.
Great, now we’re ready with the basics, so we start with the things :
The above diagram (Figure-2) of a search question and answerx application using a retrieval augmented generation (RAG) approach where embeddings are used to identify the relevant documents before inserting them into the prompt of an LLM for summarization for the end user.
The application is split into two main processes.
- First, the index creation where documents are divided into chunks which are used to generate embeddings and stored in a vector database for low latency searches.
- The second phase when the user asks a question to the system that is embedded using the query portion of the model and which will map to relevant documents when using a similarity search in the vector database. This second phase is very latency sensitive as the end user is actively waiting for a response so the ability to identify relevant documents from a large corpus in milliseconds using a vector database of documents is a critical piece of infrastructure.
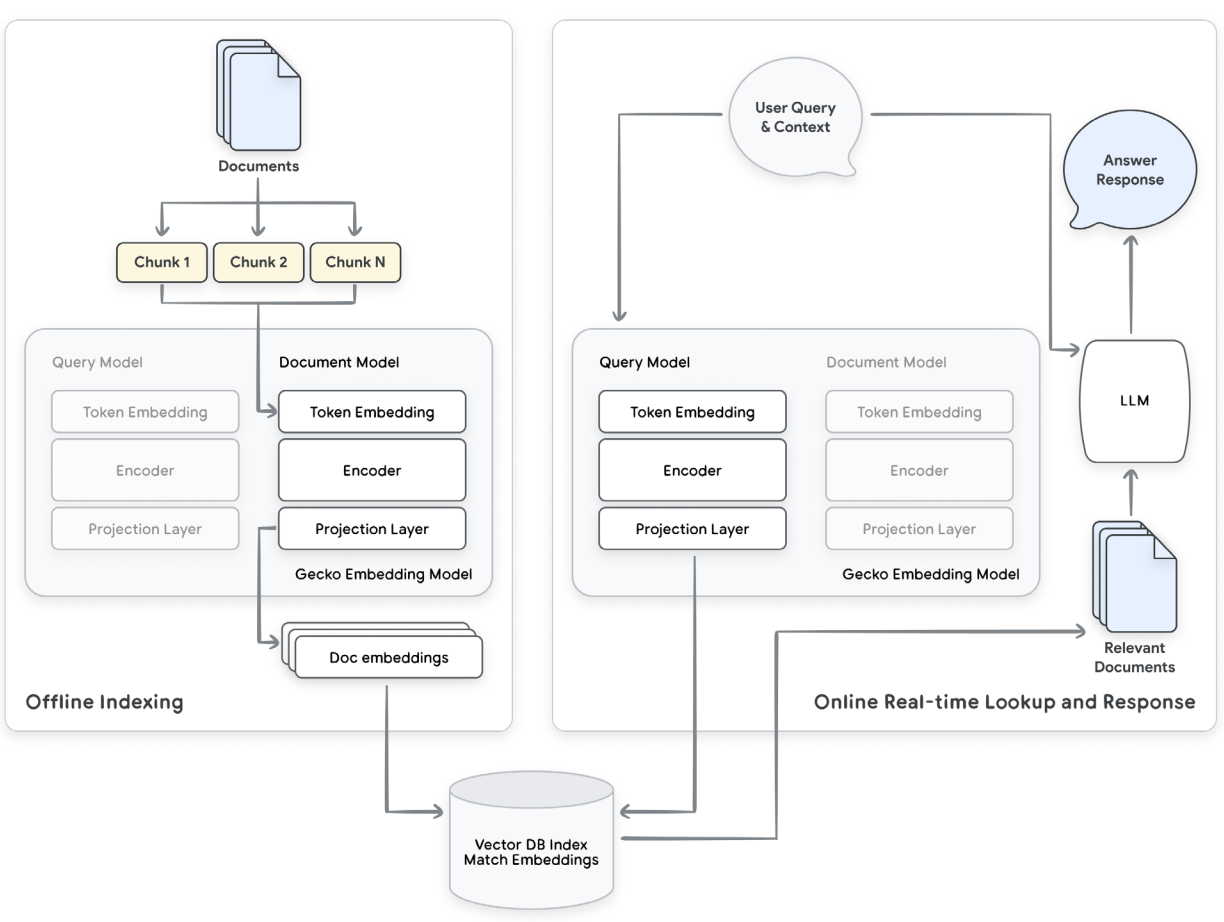
Figure — 3: Example flow for RAG Search Application highlighting embeddings. Document embeddings are generated in the background and stored in a vector database. When the user enters a query, an embedding is generated using the query embedding portion of the dual encoder and used to look up relevant documents. Those documents can be inserted into the prompt for LLM to generate a relevant summary response for the user. (I copy-pasted from Google’s Whitepaper)
So that’s it there are various opensource available that you can use to directly create these in a very short of amount of time. I’ll attach some references below.
References to implement RAG with LLMS (I’ll use LlaMa Index):
- Using Langchain (popular framework to build above systems)
- a Good repo covering all from data loading to indexing to vector to chat but quite old —
- Multi Modal RAG using Langchain —
Let’s dive into Types of Embeddings now .
Types of Embeddings
Text Embeddings
Text embeddings are used extensively as part of natural language processing (NLP). They are often used to embed the meaning of natural language in machine learning for processing in various downstream applications such as text generation, classification, sentiment analysis, and more. These embeddings broadly fall into two categories: token/word and document embeddings.
Before diving deeper into these categories, it’s important to understand the entire lifecycle of text: from its input by the user to its conversion to embeddings.

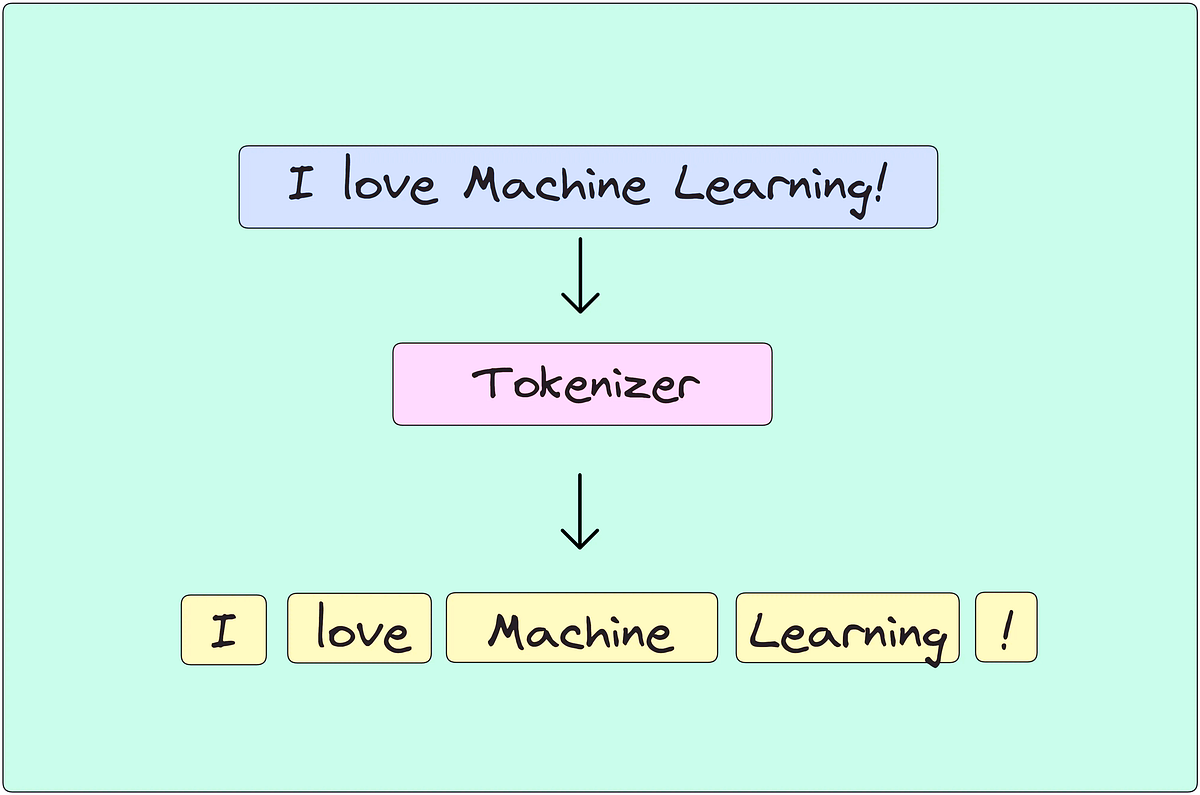
How Embeddings gets made
Steps :
- It all starts with the input string which is split into smaller meaningful pieces called tokens. This process is called tokenization.
- Commonly, these tokens are wordpieces, characters, words, numbers, and punctuations using one of the many existing tokenization techniques.
- So we know that tokens are nothing but smaller pieces of words/sentences only, but how they are made and what separattes them from simply — words/sentences, why the hell do we need to use another term of the same thing ?
Well, token are created by ‘tokenizing’ words (or CS term of this as well, wait … the “string”).
- After the string is tokenized, each of these tokens is then assigned a unique integer value usually in the range: [0, cardinality of the total number of tokens in the corpus].
- For example, for a 16 word vocabulary the IDs would range between 0–15. This value is also referred to as token ID.
- For example, {abcd} → tokenize {‘a’, ‘b’, ‘c’, ‘d’} — now it depens upon the data how the strings we want the tokenization process, here for simplicty I did ‘character-level’ tokenization.
- then they are converted into encoding (in simple words, assigned a unique number). For example, {a-1, b-2, c-3, d-4}
To read more how large tokenisation and endoing works (most popular One-Hot encoding, really hot), check this cool blog —
Word Embeddings
Here we’ll see a few word embedding techniques and alrogihtms to both train and use word embeddings which were precusors to the modern text embedding currently being used. While there are many ML algos developed over time optimized for different objectives, the most common ones were GloVe, SWIVEL, and Word2Vec.
Don’t worry these are not names of weapons developed by Lockheed Martin, but simple tools that converts your cute words into mathematical numbers for retarded computers to understand what we’re trying to say.
Do we need to learn these or what the hell they are ? Well these are pre-built libraries by smart guys and get our job done by just importing python libraries in few lines without going under-the-hood complexity of anything of these.
Let’s have a quick look at each :
- Word2Vec: Word2Vec is a predictive model that learns word embeddings by looking at how words appear in context. It comes in two flavors: CBOW (Continuous Bag of Words), which predicts a word from surrounding words, and Skip-gram, which predicts surrounding words from a single word. For example, given the sentence “The cat sat on the mat”, Word2Vec would learn that “cat” and “dog” often share similar contexts and should have similar vector representations. This method captures semantic similarity — words used in similar ways end up close in vector space.
- GloVe (Global Vectors for Word Representation): GloVe creates word embeddings by analyzing word co-occurrence statistics from a large corpus. It builds a matrix of how frequently words appear together and factorizes this matrix to produce word vectors. Unlike Word2Vec, which focuses on local context, GloVe captures global relationships between words. For instance, if “ice” and “snow” often appear near each other and far from “fire”, their vectors will reflect that, helping the model understand that “ice” and “snow” are related in meaning.
- SWIVEL: Swivel improves on GloVe by also handling unseen word pairs — those that don’t appear together in the data but still carry meaningful information. It uses a co-occurrence matrix like GloVe but adds a technique to estimate missing values, allowing it to learn better embeddings for rare words. For example, even if “banana” and “sled” never appear together, Swivel can still infer their relative positions using other overlapping word relationships, making it more robust, especially in sparse datasets.
Alright so here’s our embeddings.
Now we got info about embeddings, vectors, and but how the search actually works when it comes to vectors/embeddings.
Vector Search
Search is not something peculiar to us, we all do keyword based search while either searching on google or our devices.
Infact full-text-keyword search has been the lynchpin of modern IT systems for years. Full-text search engines and databases (relational and non-relational) often rely on explicit keyword matching.
For example, if you search for ‘cappuccino’ the search engine or devices returns all documents that mention the exact query in the tags or text description.
However, if the key word is misspelled or described with a differently worded text, a traditional keyword search returns incorrect or no results.

This is where Vector Search shines.
Vector search lets you to go beyond searching for exact query literals and allows you to search for the meaning across various data modalities. This allows you to find relevant results even when the wording is different. After you have a function that can compute embeddings of various items, you compute the embedding of the items of interest and store this embedding in a database. You then embed the incoming query in the same vector space as the items. Next, you have to find the best matches to the query.
This process is analogous to finding the most ‘similar’ matches across the entire collection of searchable vectors: similarity between vectors can be computed using a metric such as euclidean distance, cosine similarity, or dot product.
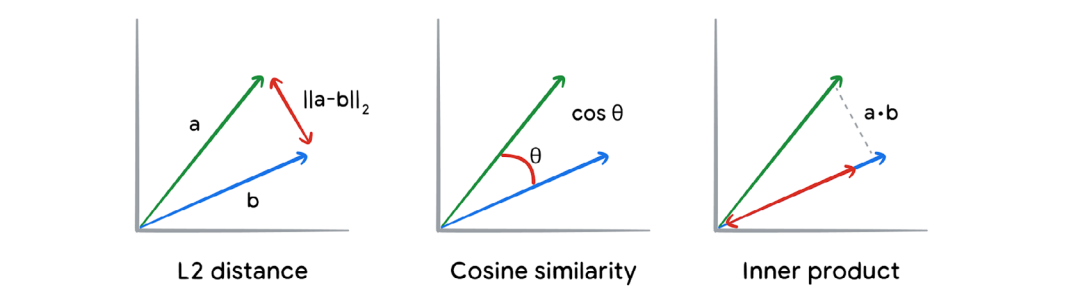
Let’s have a look at these guys, in simple words, using these three we can increase the ability of recognising complex similarities
- L2 Distance: Measures the straight-line distance between two vectors — the smaller the distance, the more similar they are.
This works well for lower dimensions. - Cosine Similarity: Measures the angle between two vectors — values range from -1 (opposite) to 1 (identical direction), ignoring magnitude.
This seems to work better for higher dimensional data. - Inner product: Calculates how much two vectors point in the same direction — higher values mean more similarity.This also seems to work better for higher dimensional data.
Alright so we know vectors, embeddings, search and improvements of it, but handling such might require an infrasturcture, just like we use databases like MongoDB, mysql, etc to store information, vectors are have a dedicated databases called … Vector Databases.
But a geniune questions, is why separate db? can’t we just store them in mysql, postgresql ?
Vector Databases
Well see there are traditional databases like MongoDB, mysql, etc, but vector embeddings embody semantic meanings of data, while vector search algorithms provide a means for efficiently querying them.
Historically traditional databases lacked the means to combine semantic meaning and efficient querying. This is what gave rise to vector databases, which are built ground-up to manage these embeddings for production scenarios.
Obvisouly due to the recent popularity of Generative AI, an increasing number of traditional databases are starting to incorporate supporting vector search functionality in addition to traditional search (‘hybrid search’) functionalities.
Let’s look at the workflow for a simple Vector Database, with hybrid search capabilities.
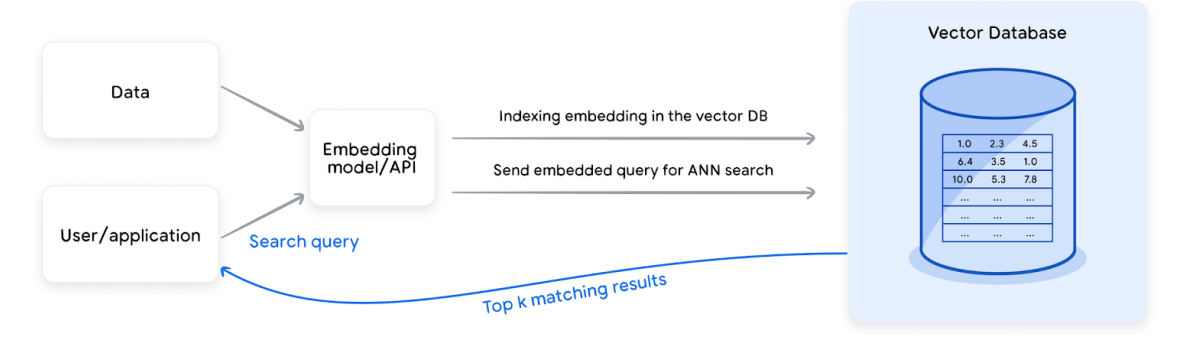
- An appropriate trained embedding model is used to embed the relevant data points as vectors with fixed dimensions.
We can use private ones like OpenAI provides or opensource from hugging face, instead of trainig models from scratch. - The vectors are then augmented with appropriate metadata and complementary information (such as tags) and indexed using the specified algorithm for efficient search.
- An incoming query gets embedded with the appropriate model, and used to search for the most semantically similar items and their associated unembedded content/metadata.
- Some of examples of popular Vector DBs, are PineCone (Paid), ChromaDB(Opensource), Weavite(Hybrid), etc
Conclusion
In this, we have discussed various methods to create, manage, store, and retrieve embeddings of various data modalities effectively in the context of production-grade applications. Creating, maintaining and using embeddings for downstream applications can be a complex task that involves several roles in the organization. Few points.
- Choose your embedding model wisely for your data and use case (don’t just go for OpenAI embedding model, just because everyone is using it). If no existing embedding models fit the current inference data distribution, fine-tuning the existing model can significantly help on the performance.
Another tradeoff comes from the model size. The large deep neural network (large multimodal models) embedding models usually have better performance but can come with a cost of longer serving latency. Using Cloud-based embedding services can conquer the above issue by providing both high-quality and low-latency embedding service. For most business applications using a pre-trained embedding model provides a good baseline, which can be further fine-tuned or integrated in downstream models. In case the data has an inherent graph structure, graph embeddings can provide superior performance (Neo4js is a good example for this) - Once your embedding strategy is defined, it’s important to make the choice of the appropriate vector database that suits your budget and business needs. It might seem quicker to prototype with available open source alternatives, but opting for a more secure, scalable, and battle-tested managed vector database can save significant developer time.
- Embeddings combined with an appropriate ANN powered vector database is an incredibly powerful tool and can be leveraged for various applications, including Search, Recommendation systems, and Retrieval Augmented Generation for LLMs. This approach can mitigate the hallucination problem and bolster verifiability and trust of LLM-based systems.
- Everything comes down to data processing, cleaning, embedding and better, faster, accurate retrieval of data from the DBs, LLMs comes second.
As traditional saying goes in ML:
Much of the intelligence and ‘magic’ of AI models is not in the math or the architecture, but comes from the data they are trained on.
that’s it.