Why Manufacturers Need an AI Plant Exception Control Layer Beyond ERP and MES Alerts
TL;DR: An AI plant exception control layer is becoming the real industrial software upgrade because manufacturers need machine, quality, supplier, maintenance, and finance decisions to move faster than ERP queues and MES alerts allow. The 2026 signal stack is unusually clear: Con

TL;DR: An AI plant exception control layer is becoming the real industrial software upgrade because manufacturers need machine, quality, supplier, maintenance, and finance decisions to move faster than ERP queues and MES alerts allow. The 2026 signal stack is unusually clear: Consultancy.eu reported that Stellantis selected Accenture for AI and digital twin manufacturing transformation with NVIDIA involvement; Harvard Business Review argued that the best manufacturers build AI with workers, not for them; KPMG's Global Tech Report 2026 kept AI high on the industrial agenda; SAP used Hannover Messe 2026 to promote agentic AI for resilient end-to-end manufacturing; and Fierce Network reported that Dell is building a sovereign AI stack for the on-prem era.
The question is no longer whether AI will enter plant operations. It already has. The real question is where the workflow boundary lives once AI starts deciding how production exceptions get handled across systems.
If your plant still needs humans to pull context from ERP, MES, quality systems, maintenance logs, supplier updates, and finance workflows before anything useful happens, you do not have an analytics problem. You have an execution-architecture problem.
Why is manufacturing AI moving beyond ERP and MES alerts?
Because the hard part of plant operations is not noticing that something changed. It is deciding what to do next when production reality stops matching the plan.
ERP is still useful as a system of record. MES still matters for line visibility. Quality systems document defects. Maintenance tools track service history. Procurement systems know what suppliers promised. Finance records the cost and revenue consequences after the fact. But the actual industrial judgment lives between these tools, not inside any one of them.
A line begins drifting. Scrap risk rises on one family of parts. A supplier delay threatens the next shift. Maintenance can see a machine pattern, but not the downstream customer consequence. Quality sees nonconformance history, but not the commercial trade-off. Finance cares because expedite and delay costs are about to move. Support may already be hearing customer anxiety before the morning review catches up. The software stack may be crowded, but the decision path is still manual, fragmented, and slow.
The 2026 signal stack makes that impossible to ignore. Consultancy.eu reported that Stellantis selected Accenture for AI and digital twin manufacturing transformation with NVIDIA involvement. Harvard Business Review argued that the best manufacturers build AI with workers, not for them. KPMG's Global Tech Report 2026 kept AI high on the industrial manufacturing agenda. SAP used Hannover Messe 2026 to promote agentic AI for resilient end-to-end manufacturing. Fierce Network reported that Dell is building a sovereign AI stack for the on-prem era. Put together, the message is blunt: industrial AI is moving from dashboards and copilots toward live workflow execution, and manufacturers now have to decide who owns that action layer.
Direct answer: Manufacturing AI is moving beyond ERP and MES alerts because plants do not fail one application at a time. Real exceptions cross operations, quality, maintenance, suppliers, finance, and customer commitments, and the response has to move across all of them.
What is broken in the old plant exception operating model?
Take a representative scenario. A supplier shipment slips and creates risk on a constrained line. Maintenance already knows a machine in that cell has elevated failure probability. Quality has seen subtle drift on the last two runs. Procurement knows the alternate component is available but needs approval. Finance wants to avoid an unnecessary expedite if the line can be resequenced. Customer support may already be fielding delivery concerns from a key account. None of those signals is useless. The problem is that they rarely arrive in one governed workflow at the exact moment the decision has to be made.
So humans compensate. They export reports. They walk across the plant. They compare yesterday's ERP state with this hour's machine reality. They ask quality whether the signal is real or noise. They ask procurement how real the ETA is. They ask finance whether the cost hit is acceptable. They make the supervisor or planner act as the unofficial integration layer between systems that were never designed to coordinate judgment elegantly.
This is where generic industrial AI demos tend to collapse. A model that can summarize an incident without governed access to machine history, quality trends, supplier risk, inventory exposure, approval policy, and commercial impact is just a nicer dashboard. Manufacturers do not need an industrial chatbot that sounds informed. They need a workflow layer that collects the right evidence, applies local policy, and triggers the next safe action.
The deeper issue is commercial as much as technical. Once the workflow boundary sits inside an ERP add-on or cloud vendor product, the operator starts renting critical judgment: which data is visible, which write-backs are supported, where approval rules live, how fast policy can change, and how costly it becomes to switch later. In an AI-heavy industrial environment, that is not a feature decision. It is control over how the business reacts under pressure.
Direct answer: The old plant exception model breaks because industrial decisions depend on cross-system context and governed action, while legacy workflows mostly record activity after the fact instead of orchestrating the messy exception work that keeps factories moving.
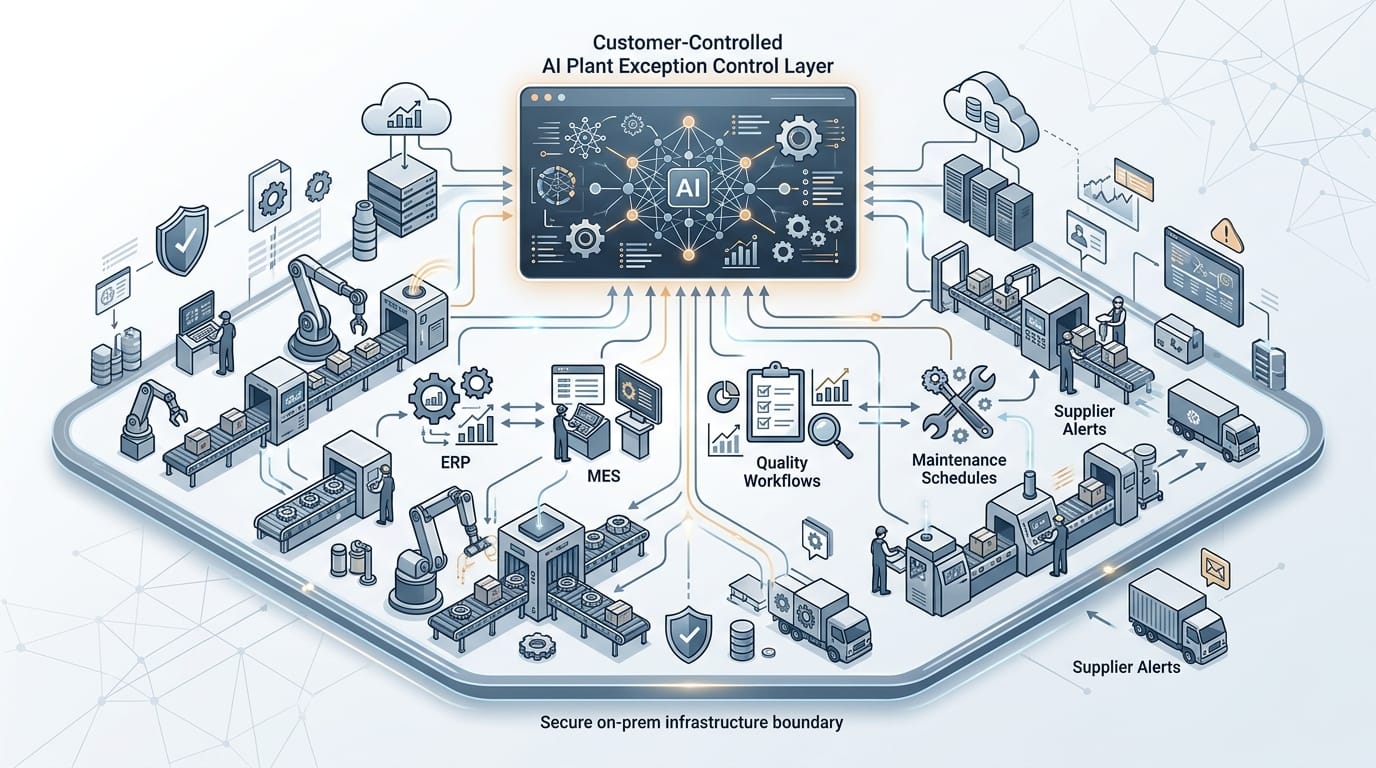
What does an AI plant exception control layer actually look like?
It looks less like a copilot and more like a customer-controlled workflow engine that sits above brittle handoffs.
The first layer is connectors. Without them, industrial AI stays theatrical. A serious plant exception workflow needs governed access to ERP, MES, quality systems, maintenance records, procurement systems, supplier feeds, ticketing tools, and finance metrics. This is where many pilots quietly fail. They assume the hard work starts with model selection. It does not. In production, integration design is the product. That is why cross-system connectors matter so much: they define whether the AI sees live plant truth or stale fragments.
The second layer is context assembly. Useful manufacturing AI does not dump raw tables into a model and hope for the best. It retrieves the exact evidence needed for the workflow: line state, downtime pattern, defect history, supplier reliability, inventory position, alternate routing options, approval thresholds, and customer exposure. That shifts the system from reporting to decision support with teeth.
The third layer is policy. Some actions can be automated. Some should be recommended with approval. Some must stay human-controlled because of safety, contractual, or regulatory constraints. A customer-controlled architecture keeps those rules in a boundary the manufacturer owns. That matters in Europe for governance and intervention-path clarity. It matters in the US because operators still need to inspect, adapt, and defend how decisions are made when throughput and margin are on the line.
The fourth layer is execution. Advice alone is cheap. The value appears when the system can open or enrich a maintenance ticket, trigger a quality hold recommendation, draft a supplier escalation, reroute work, prepare a procurement exception, update support guidance, and write an approved outcome back into the system of record with a clean audit trail. That is the operating shape InfraHive is built for: customer-controlled AI data processing and workflow automation running on infrastructure the customer owns, with zero ambiguity about where the data and decision boundary live.
The fifth layer is measurement. If the workflow layer cannot connect its actions back to scrap risk, downtime, expedite cost, order delay, first-pass yield, or margin impact, then it is just faster confusion. This is why a measurement spine like MetricFlow matters. It ties operational automation to economics instead of vanity dashboards.
The platform story matters too. Manufacturers should not buy a separate AI brain for every function. The same workflow engine that triages a plant exception can also automate invoice processing in Finance or resolve Tier-1 internal requests in IT. It is one platform, configured differently. That matters because plant operations, finance, support, and IT do not live in cleanly separated worlds even if software vendors price them that way.
Direct answer: An AI plant exception control layer combines governed connectors, workflow-specific context retrieval, a local policy boundary, auditable write-backs, and customer-controlled deployment so industrial decisions can move faster without surrendering control.
How do you implement this without another giant transformation program?
By refusing to start with a slogan and starting with one ugly workflow instead.
The wrong kickoff is, "We need agentic manufacturing." That is how teams buy a concept. The right kickoff is choosing one exception path that already burns time, margin, or customer trust: delayed supplier response, recurring maintenance triage, nonconformance routing, engineering-change handoff friction, inspection backlog escalation, or plant-to-finance reconciliation after a production disruption.
Implementation usually has three layers. First, evidence mapping: which systems hold trustworthy state, which signals arrive late, where approval thresholds really sit, and which team actually owns the decision today. Second, policy design: what the system may do automatically, what it may recommend with approval, and what must remain human-only. Third, rollout: one plant, one line, one defect family, one supplier class, or one maintenance scenario first, with tight measurement around cycle time, override rate, downtime exposure, and financial impact.
The forward-deployed model matters because industrial architecture diagrams lie. The stack slide says ERP, MES, quality, and maintenance are integrated. Operators know better. Somebody has to sit with plant leaders, maintenance planners, quality engineers, procurement owners, and finance teams and map where truth actually lives. Somebody has to encode policy around reality instead of vendor mythology. That is why the strongest deployments begin with a painful operating path, not a generic AI platform rollout.
The objections are predictable. "Our ERP environment is too customized." Fine. That is an argument for an execution layer above it, not against one. "We cannot rip and replace." Good. Do not. "Our vendor already has AI." Also fine, but an in-suite assistant rarely sees the full economics of decisions that cross plant, supplier, quality, finance, and support boundaries. "We need a business case." Then start where the current process already creates downtime, scrap, expedite cost, or missed commitments.
The migration path is almost always hybrid. Keep ERP and plant systems as systems of record if they still earn that role. Replace the brittle workflow layer first. That lets the manufacturer reclaim judgment work without betting the whole estate on one giant program. It also turns connectors, approvals, monitoring, and logging into reusable assets for the next workflow instead of one-off project debris.
Direct answer: Real implementation starts with one painful exception workflow, maps messy reality first, builds governed connectors and policy controls, uses a forward-deployed builder to bridge teams, and expands through a measured hybrid rollout.
What results should manufacturers actually expect?
When judgment-heavy work moves into a manufacturer-owned execution layer, teams spend less time gathering context manually. Exceptions move faster because the system assembles evidence, applies policy, and prepares the next action before humans waste a shift chasing the state across tools. Maintenance gets earlier signals with better context. Quality sees recurring patterns faster. Procurement reacts to supply volatility with less chaos. Finance gets earlier visibility into operational cost and revenue effects.
The second result is control. A customer-owned workflow layer is easier to inspect, adapt, and audit than a patchwork of SaaS AI features. The same connector patterns that support plant exceptions can support finance close workflows, IT operations, or customer support. That is the strategic point behind InfraHive's platform story. The same workflow engine that processes invoices in Finance can also resolve Tier-1 IT tickets or coordinate manufacturing exceptions. One platform. Different configurations. Shared control boundary.
The third result is compounding capability. Once the execution layer is customer-controlled, the business can change systems beneath it over time without restarting from zero. That lowers lock-in pressure while increasing reuse across the estate. You can see the same pattern in customer deployment outcomes and security and deployment design: the first use case may be narrow, but the operating layer becomes reusable.
Direct answer: Expect faster exception resolution, fewer manual touches, better visibility into operational and financial impact, and a reusable automation layer that compounds across manufacturing, finance, IT, and support.
What does this mean for manufacturers in Europe and the US?
It means AI advantage will increasingly belong to the operator who owns the workflow boundary, not the operator who buys the flashiest industrial demo.
In Europe, that boundary increasingly intersects with sovereignty, governance, supplier exposure, and intervention-path expectations. In the US, the same architecture shows up as throughput, resilience, and margin discipline. Different language, same engineering reality: the closer AI gets to live industrial decisions, the less sensible it is to leave the action layer inside a vendor black box.
The early movers will not just add intelligence to dashboards. They will strip exception-heavy work out of ERP-centric operating loops and rebuild it as controlled, inspectable systems that fit how factories actually run.
Direct answer: In both Europe and the US, manufacturers that own their AI workflow boundary will modernize faster and with less lock-in risk than those waiting for ERP or cloud vendors to solve the problem for them.
So what should a manufacturer do next?
Pick one workflow where people are still acting as the integration layer between ERP, plant systems, suppliers, finance, and reality. Rebuild that path first. Keep the systems of record if you need them. Just stop pretending the judgment layer belongs inside old enterprise software.
If you want a practical view of customer-controlled workflow AI running on infrastructure you control, start at https://infrahive.ai, review deployment control and security, inspect connector coverage, and explore how this works for your stack. The strategic choice is not whether AI will enter manufacturing operations. It is whether your team gets to own the part that matters.
Direct answer: Start with one ugly exception workflow, own the control boundary, prove the economics, and expand from there.
Frequently Asked Questions
What is an AI plant exception control layer?
It is a customer-controlled workflow layer that connects ERP, MES, quality, maintenance, procurement, support, and finance systems so AI can assemble context, apply policy, and trigger auditable industrial actions.
Does this mean replacing ERP or MES?
No. Most manufacturers keep ERP and plant systems as systems of record and replace the judgment-heavy workflow layer around them first.
Which manufacturing workflows are best to start with?
Maintenance triage, supplier-delay response, nonconformance routing, inspection backlog escalation, and plant-to-finance exception handling are strong starting points because they already span multiple systems and teams.
Why does on-prem or sovereign deployment matter?
Because the strategic asset is not only the data. It is the policy logic, action rights, approvals, and audit boundary that determine how the manufacturer responds when operations drift off plan.
What is the biggest mistake in manufacturing AI projects?
Treating the model as the product. In production, the real product is the connector boundary, policy layer, write-back logic, and measurement system wrapped around the model.